

















 sur Amazon")
")

Pour les équipes qui construisent des modèles complexes de l’auto-apprentissage, le temps et le coût sont des considérations importantes. Dans le Cloud, différents types d’instances peuvent être utilisés pour réduire le temps nécessaire au traitement des données et à la formation des modèles.
Les unités de traitement graphique (GPU) offrent de nombreux avantages par rapport aux processeurs (CPU) lorsqu’il s’agit de traiter rapidement de grandes quantités de données typiques dans les projets d’apprentissage automatique. Cependant, il est important que les utilisateurs sachent comment surveiller l’utilisation pour s’assurer que vous ne surchargez pas ou ne sous-provisionnez pas les ressources de calcul (et que vous ne payez pas trop pour les instances).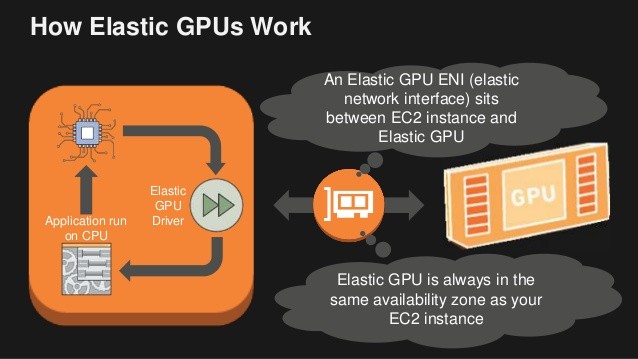 AWS propose plusieurs types d’instances GPU pour son Elastic Compute Cloud (EC2) qui visent à prendre en charge des applications à la fois intensives en calcul et nécessitant une vitesse de performance plus rapide. Par exemple, en utilisant la nouvelle instance de GPU d’AWS, P3, Airbnb a été en mesure de parcourir plus rapidement et de réduire les coûts de ses modèles d’apprentissage automatique qui utilisent plusieurs types de sources de données.
AWS propose plusieurs types d’instances GPU pour son Elastic Compute Cloud (EC2) qui visent à prendre en charge des applications à la fois intensives en calcul et nécessitant une vitesse de performance plus rapide. Par exemple, en utilisant la nouvelle instance de GPU d’AWS, P3, Airbnb a été en mesure de parcourir plus rapidement et de réduire les coûts de ses modèles d’apprentissage automatique qui utilisent plusieurs types de sources de données.
Notre nouveau laboratoire «Analyser les performances du CPU par rapport à celles du GPU pour AWS Machine Learning» aidera les équipes à trouver le juste équilibre entre coût et performance lors de l’utilisation des GPU sur AWS Machine Learning.
Vous prendrez le contrôle d’une instance P2 pour analyser les performances du CPU par rapport au GPU et vous apprendrez comment utiliser l’AWS Deep Learning AMI pour démarrer un serveur Jupyter Notebook, qui peut être utilisé pour partager des données et des expériences d’apprentissage automatique.
Dans cette vidéo, Logan Rakai, vous donnera un aperçu de ce que vous apprendrez dans ce laboratoire pratique.
 pour Kodi en 2025")




{kind=link}